Auditable Database Storage... What's Different?
Nick Merlino and Andy Merlino
2020/05/06

This is a followup post to the Shiny CRUD blog post. The Shiny CRUD blog post covers how to build a Shiny app that is capable of Creating, Reading, Updating, and Deleting records from a database. This post describes an auditable alternative to CRUD. Auditable data storage requires that you never lose any information; the historical state of the data must be preserved. To achieve auditability, we never delete or update rows in the database tables. Instead we mark deleted rows as deleted and add a new row into the database table each time there is a data update.
We created a simple demo Shiny app that implements auditable database storage:
The remainder of this post will give a high level overview of the above app, and it will compare and contrast the auditable database approach with the traditional CRUD app from the previous post.
To dive deep and learn about the nuances of this implimentation you can explore the app code here:
Please feel free to make suggestions for improvements in the comments and on GitHub!
Data Prep
Our Shiny app uses the well-known mtcars dataset. Like in the Traditional CRUD app, we made some minor alterations to the mtcars dataset which can be found in the “data_prep/data_prep.R” script.
Also in the “data_prep/” folder, we created a “db_init.R” script. This script is used to define the database schema and seed the database with the cleaned mtcars data. You should be able to run the “data_prep/data_prep.R” and “data_prep/db_init.R” scripts to reproduce our data prepartion and the creation of the initial database.
Similarities with Traditional CRUD
From the user’s perspective the app functions identically to the Traditional CRUD app:
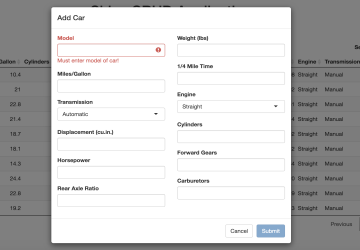


Differences from Traditional CRUD
The traditional CRUD app implements data Create, Read, Update, and Delete operations. The auditable variation has only Create and Read. In the auditable variation, rather than deleting the car from the table entirely, we insert a new row for the car with a value of 1 (SQLite stores booleans as integers – 1 for TRUE and 0 for FALSE) for the “is_deleted” column. When reading in the data, we filter out all but the most recently updated row for each car. We then filter out cars with “is_deleted” values of 1.
To get the current data we simply read in the most recently modified row for each car using dplyr:
conn %>%
tbl("mtcars") %>%
select(-uid) %>%
collect() %>%
mutate(
created_at = as.POSIXct(created_at, tz = "UTC"),
modified_at = as.POSIXct(modified_at, tz = "UTC")
) %>%
# find the most recently modified row for each car
group_by(id_) %>%
filter(modified_at == max(modified_at)) %>%
ungroup() %>%
# filter out deleted cars
filter(is_deleted == 0) %>%
arrange(desc(modified_at))Since we do not ever delete or update any data, we can read in our cars table at any historical point in time. e.g. To get the “mtcars” data as of 30 days ago we could run:
conn %>%
tbl("mtcars") %>%
select(-uid) %>%
collect() %>%
mutate(
created_at = as.POSIXct(created_at, tz = "UTC"),
modified_at = as.POSIXct(modified_at, tz = "UTC")
) %>%
# filter for data as of 30 days ago
filter(modified_at <= Sys.Date() - lubridate::days(30)) %>%
# find the most recently modified row for each car
group_by(id_) %>%
filter(modified_at == max(modified_at)) %>%
ungroup() %>%
# filter out deleted cars
filter(is_deleted == 0) %>%
arrange(desc(modified_at))Conclusion
This auditable approach to database storage gives us access to the historical state of our data at any point in time. This level of historical detail is mandatory for many business applications.
For this demo app, we traded efficiency for simplicity; our simple approach is not appropriate for large data sets. A few tweaks to the database and queries could help it scale to larger data. Additional changes would be needed as you continue to scale to bigger and bigger data.
Auditability is required by many applications, but it does come with the overhead of making your data larger and more complicated. We recommend the traditional CRUD approach if you do not require auditability. In general, keep it as simple as possible.
We hope this simple demo can give you a jump start if you ever need to implement similar functionality in a Shiny app.
comments powered by Disqus