Shiny CRUD
Andy Merlino
2020/01/29
NOTE: This post assumes knowledge of R and Shiny and some familiarity with databases. If you are new to R and Shiny, there are great learning resources at https://shiny.rstudio.com/. If you are comfortable with R and Shiny, but the idea of persistent data storage is new to you, then first read Dean Attali’s excellent post on persistent data storage
Background
The ability to persist data across user sessions is a very common requirement for web apps. e.g. A to-do app is a basic app requiring persistent storage. In a to-do app, the user can add an item to their to-do list and close the app. The next time the user opens the app, they can view the previously created to-do item (the to-do item has persisted). The user can then edit or delete the to-do item and those changes will then persist to future user sessions.
While a to-do app is one of the simplest apps requiring persistent data storage, there is no shortage of apps requiring the same fundamental actions for creating, reading, updating, and deleting persistent data. These data requirments are so ubiquitous that apps implementing Create, Read, Update, and Delete database functionality are often referred to as CRUD apps. In this blog post, we demonstrate how to create a simple CRUD app with R and Shiny. We will use SQLite for our database.
At Tychobra, we regularly add CRUD functionality to Shiny. In doing so, we have adopted a few techniques that improve the code and UX of CRUD in Shiny. The goal of this post is to share our Shiny CRUD knowledge, and hopefully improve how we work with databases in the future. Please feel free to make suggestions for improvements in the comments and on GitHub!
App Overview
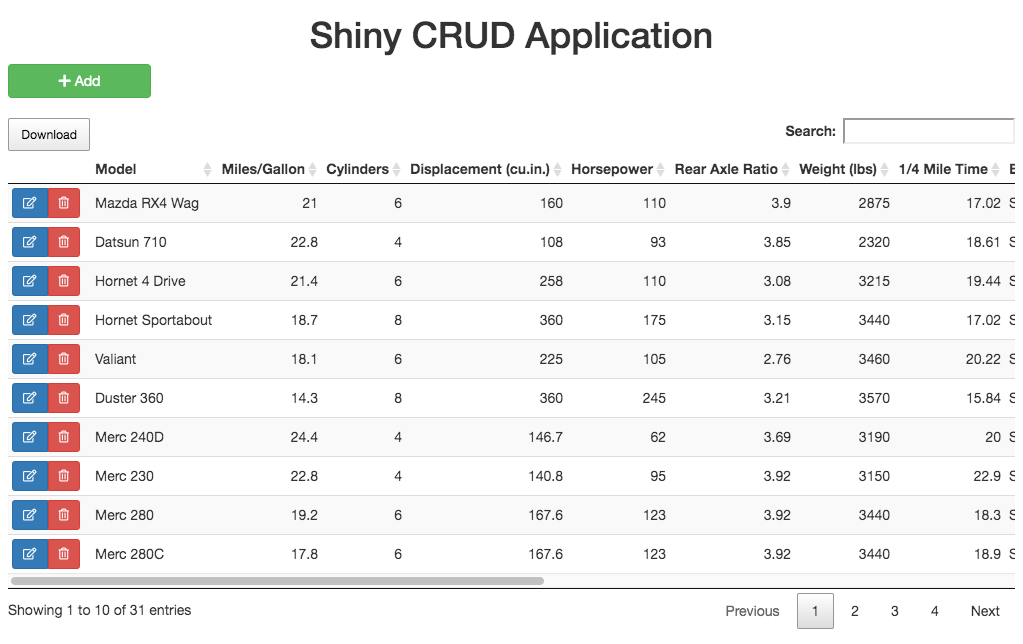
Our Shiny app uses the well-known mtcars dataset. The user will be able to create, read, update, and delete cars from this table of cars.
Data
First we prepare the mtcars data frame for the database. If you open “data_prep/data_preps.R” you can see we made a few simple data adjustments and created a new “uid” column to use for the primary key in the database.
Also in the “data_prep/” folder, we created a “db_init.R” script. This script is used to define the database schema and seed the database with the cleaned mtcars data.
In “db_init.R”, we add four columns to the “mtcars” database table to keep records of any data additions or modification: “created_at”, “created_by”, “modified_at”, and “modified_by”. Finally, we write the data to a new database at this location “shiny_app/data/mtcars.sqlite3”. This is the database that our Shiny app will use.
You should be able to run the “data_prep/data_prep.R” and “data_prep/db_init.R” scripts to reproduce our data prepartion and the creation of the initial database.
The Shiny App
Everything the deployed Shiny app needs to run is saved in the “shiny_app/” folder. When we are ready to deploy the app, we will only deploy the “shiny_app/” folder to our server (in this case shinyapps.io). Data preparation and other scripts that are not needed at application run time go in “data_prep/” or other folders in the root R project folder.
Modules
We aim to modularize nearly all the functionality in any Shiny app. We define all our modules in the “shiny_app/R/” folder. Please open the live app and/or inspect the code to understand how the modules work! The links are above.
Overview
Our CRUD app includes 3 modules: car_table_module, car_edit_module, and car_delete_module. We create 2 instances of the car_edit_module. One instance is used to update the cars, and the other is used to create new cars.
Cars Table Module
Car Add/Edit Module
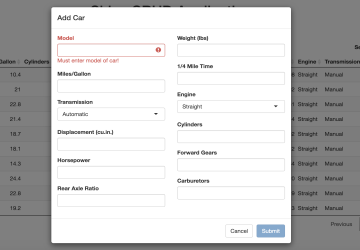

Car Delete Module

Our Database Practices
The following bullets give a high level summary of our database practices:
wrap queries in
tryCatch(): the code blocks that create, update, and delete data from the database are executed within thetryCatch()function. If an error occurs when executing the try code block (e.g. the network connection is lost), we can then properly handle the error.show user feedback: We use the
shinyFeedbackpackage to send either success or error toast messages after attempting a database create, update, or delete. We also useshinyFeedbackto show messages alongside Shiny inputs. And we useshinycssloadersto show CSS spinners while outputs are loading.use
DBIanddplyrfor queries: We write parameterized queries with theDBI::dbExecute()function to perform all create, update, and delete database queries. Parameterized queries guard against SQL injection. We usedplyrto execute the GET queries to read data using the familiardplyrsyntax.DT::datatableProxy(): for most DT tables we useDT::datatableProxy()which allows us to reload the data in the datatable without rerendering the entire table. The proxy allows the datatable to maintain it’s current page after a data update, and it minimizes the table flashing when rendered.Add buttons to
DT::datatable(): we like to add action buttons to each row of the datatable to edit, delete, and perform other actions on specific rows. The buttons communicate with Shiny using custom JavaScript event handlers. You can find the JavaScript in “shiny_app/www/cars_table_module.js”Use reactive triggers to reload db data: We create a
shiny::reactiveVal()named "*_trigger" directly above each reactive that reads in data from the database. We then attach these reactives to session$userData, so we can increment them from within nested Shiny modules. These reactive triggers are used to reload data from the database after a successful create, update, or delete query.
If you are looking for an in depth understanding of our preferred CRUD applications techniques please check out the Shiny app source code.
Our Database Questions
should we switch from
DBItopool? We encountered some issues with an old version of MySQL (5.6 IIRC) andpool, but if pool works better for all modern DBI compatible database, we should probably consider usingpool.should we usedigestto create guids to use as the primary keys for our database tables. We prefer to use guid over auto incremented primary keys, but is digest the best way to generate these guids?- update 2020-04-15: we now use
uuid::UUIDgenerate()to create unique primary keys for almost all our tables. We have found this to work better than usingdigest.
- update 2020-04-15: we now use
Conclusion
This demo shiny app uses our favorite techniques for working with databases from Shiny. We hope this post helps you work with databases from Shiny.
There are lots of different ways to implement similar CRUD functionality. If you know of better techniques for creating CRUD apps with Shiny please share in the comments or in a GitHub issue! We would love to learn more to improve and share how we work with databases in Shiny.
comments powered by Disqus